




Pre-trained AI large language models (LLMs) have been trained on huge volumes of general text data to understand, generate, and manipulate human language. Popular examples include GPT-4 (OpenAI), Llama (Meta), Gemini (Google) and Phi (Microsoft) as well as IBM's Granite (which I covered in depth in my previous blog). They are powerful and flexible and can be used for a variety of general use cases, from summarizing documents and information retrieval to chatbot deployments.
While they have broad capabilities out-of-the-box, pre-trained LLMs often require customization if you want them to perform specialized tasks to an optimum level. For example, you might want to create a specialist customer support chatbot for a mainframe company that needs to understand technical jargon and provide instructions specific to the company's products and services. Or perhaps you need to build a legal contract review tool that flags clauses and terms that don't comply with your law firm's standards while suggesting appropriate alternatives based on past contracts.
So how do you go about customizing a pre-trained model for domain or company-specific tasks like this?
Fine-tuning
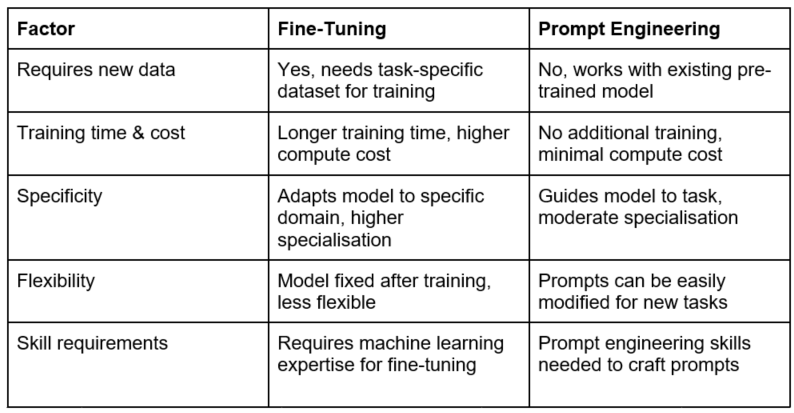
One approach is fine-tuning. This involves supplementing the model with a new data set relevant to your specific task to refine it. You would need to gather and label examples of the target task (often many thousands of examples) and use that to fine-tune the model by allowing it to be trained on that new data.
In essence, the new data provides the AI with new raw information, and training helps it absorb this data into the model (by giving the new data appropriate weightings) so it can apply it to generate the most relevant and appropriate responses.
Prompt engineering
An alternative way of customizing LLMs that doesn't require introducing new data into the model is prompt engineering. This involves serving front-end prompts or cues to your AI model so that it can narrow down responses to the specific task or area of expertise. In other words, prompt engineering is about developing prompts that guide the LLM to perform the specialized tasks you want it to.
While prompt engineering can be achieved by using hand-crafted "hard" prompts, written in natural language, it increasingly relies on delivering superior "soft" prompts designed by an AI. These soft prompts, officially known as "learned continous prompt embeddings", are sets of numeric vectors that are optimized during the fine-tuning process to guide the language model's output. Unlike hard prompts which are manually crafted text, soft prompts are not human-readable but are more effective at steering the model's focus. So with prompt engineering, instead of adding new data to be incorporated into the model with additional training, you're adjusting the model's focus using these learned numeric vectors. Because it uses less computing power, it is considered a lower-cost and more energy-efficient way of customizing an LLM.
For example, redeploying an AI model in this way without retraining it can cut computing and energy use by at least 1,000 times, which can save thousands of dollars (according to IBM's David Cox, head of Exploratory AI Research and co-director of the MIT-IBM Watson AI Lab). Improving the energy efficiency of how we use GenAI is an important issue given the dramatic increases in data center power consumption that many experts fear it will lead to. However, it's important to note that the exact energy savings may vary depending on the specific use case and the size of the LLM being used.
When to use prompt engineering
In general, prompt engineering would be the best option if you're looking for a moderate level of task specialization - and when quick experimentation and flexibility to modify tasks is important. Obviously, it will be the default approach option if you don't have the required task-specific data and need to rely on the model's existing knowledge. It's also the only option when computing resources for training are limited.
Consider a flower shop that wants to generate compelling product descriptions for its online store. They don't have a large database of existing descriptions to use for fine-tuning. However, the descriptions they need are relatively short and follow a similar format, hitting key points like the flower type, color, occasion and sentiment.
Prompt engineering could work well here. The shop could craft a template prompt like: "Write a vivid product description for a [flower type] bouquet. Describe the [color] color and why it's perfect for [occasion]. Use poetic language and evoke [sentiment] emotions."
Then they simply fill in the variables for each product. A well-designed prompt can guide the model to generate consistently structured, on-brand descriptions with minimal examples needed. In this use-case trying to fine-tune the model with the small set of examples that are available would likely be less effective.
When to use fine-tuning
Fine-tuning is more appropriate for situations in which you require a high degree of model specialization and where the consistency of the AI's response is critical. Obviously, you also need to be willing (and able) to invest the necessary resources in training and have a large, high-quality dataset specific to your task or domain.
As an example, imagine a law firm that wants to build a model to analyze its past case documents and extract key information like client names, case numbers, important dates, and legal outcomes. It will have a large database with thousands of its own case files to train on.
In this scenario, fine-tuning a pre-trained Natural Language Processing (NLP) model on the firm's specific data would likely produce the best results. The fine-tuned model could learn the unique formatting, jargon, and information structure present in the firm's documents. Prompt engineering alone would struggle to capture all those intricacies and specifics without the model being exposed to many examples from the dataset.
Emerging approaches to model customization
It's important to appreciate the rapid pace of change in this area. For example, an emerging approach to traditional fine-tuning called parameter-efficient fine-tuning (PEFT) could potentially offer more accessible and cost-effective model training depending on the complexity of the task.
Instead of fine-tuning an entire pre-trained model, PEFT works by identifying and adjusting only the most crucial model parameters relevant to a specific task. As this technique becomes more mainstream, it could mean more efficient fine-tuning - requiring less data while also using less computing power and energy.
Conclusion
Broadly speaking, prompt engineering is recommended as a starting point for customizing an LLM due to its simplicity and flexibility. It can also be used as a preliminary step to assess the feasibility of a task before investing resources in fine-tuning.
Fine-tuning can be explored for higher-value use cases where the investment in data curation and model training is justified by the business's need for a highly specialized model. A combination of both techniques is also possible, such as fine-tuning a model and further guiding it with well-crafted prompts.
I'll leave you with this table which nicely summarizes the current advice on when to use fine-tuning versus prompt engineering.
This blog was originally published on the IBM Community.